
Every great EV road trip is a journey of discovery. Last November, my partner, our golden doodle Korra, and I drove our Rivian R1S from the Seattle area to Denver. 3,000 miles. Three mountain passes. Zero gas. I came home with hundreds of photos and one nagging thought: this trip deserves better than getting buried in my camera roll.
That thought became Trail Spark — my little corner of the internet for documenting and sharing EV road trips the way they actually felt.
Where does a road trip go to live?#
Think about it. You take an incredible trip… and then what? The photos sink to the bottom of your camera roll. The group chat scrolls past in a week. The route, the charging stops, the golden-hour detour you almost talked yourself out of — all of it just fades.
But here’s the thing: your phone already saved the whole story! Every photo has a timestamp and GPS coordinates baked right in. The trip is in there — every stop, every mile — hiding in the metadata of pictures you already took.
Drop your photos, get your trip#
So that’s what Trail Spark does. You drop in your photos and it builds your road trip for you:
- A timeline of your trip, sorted automatically by time and place — no writing required.
- Your route, stops, and charging data mapped out, with milestones along the way.
- A clean, public link you can share with anyone — nothing to install to view it.
- Privacy built in — license plates get blurred automatically, so you can share freely.
No spreadsheets. No captions to agonize over. Just the photos you already took, turned into a trip you can actually relive and share!
How I pulled it off (without quitting my day job)#
Real talk: I don’t code full-time anymore, and between work and family I barely have spare hours at home. A few years ago a project like this would have died in the setup phase.
What changed? I partnered with AI. Tools like Cursor and Claude Code handled the boilerplate, the plumbing, and the gnarly debugging loops — so I could play architect instead of typist and focus on what the product should feel like.
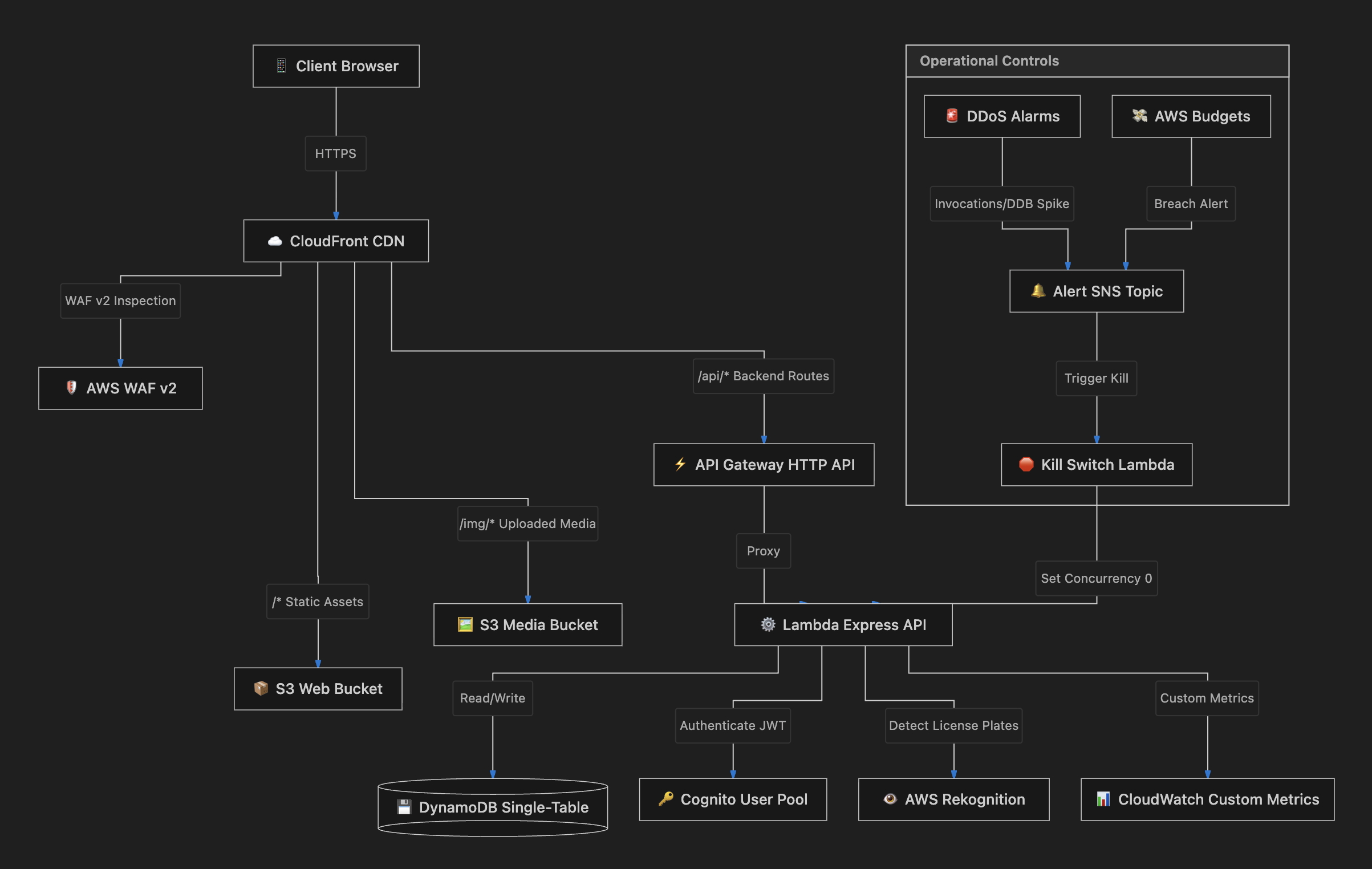
And I built the whole thing on AWS, the same cloud I work with by day (eating my own dogfood!). That means Trail Spark is fast, secure, and cheap enough to run as a hobby — it costs almost nothing when no one’s using it. I even wired up an automatic “kill switch” so a surprise traffic spike or a bad actor can never blow up my bill. Peace of mind for a project I run purely for fun!
Come map your own adventure#
Trail Spark is live at trailspark.me! I’m inviting fellow Rivian and EV road-trippers to start mapping and sharing their own trips. Drop your photos in and watch your adventure come together — your stops, your route, your milestones, all on a timeline you can share.
Next up: smarter timeline grouping, dynamic license-plate blurring, and opening the beta a little wider.
Want the full engineering breakdown — the AWS architecture, the WAF tuning, the DynamoDB single-table design, and that budget kill-switch? I wrote it all up on punitdeotale.com, my technical blog.
I build things for the EV community. I drive a Rivian R1S, travel with my golden doodle Korra, and have strong opinions about charging-station coffee.

